Sau thêm một thời gian chạy thực tế với OpenClaw, mình nhận ra kiến trúc Hybrid Memory 3 lớp + Compaction vẫn mới giải được một nửa bài toán.
Nó giúp mình trả lời khá ổn câu hỏi:
- nên lưu cái gì,
- nên để ở đâu,
- và nên nén/lọc lại khi nào.
Nhưng khi task bắt đầu dài hơn, có nhiều nhánh hơn, nhiều project hơn, hoặc có chuyện agent phải tự phối hợp main / worker / clarification, thì mình thấy còn thiếu một lớp rất quan trọng:
Context không chỉ cần được lưu. Nó còn cần được tổ chức, nạp đúng lúc, và giải thích được vì sao nó được dùng.
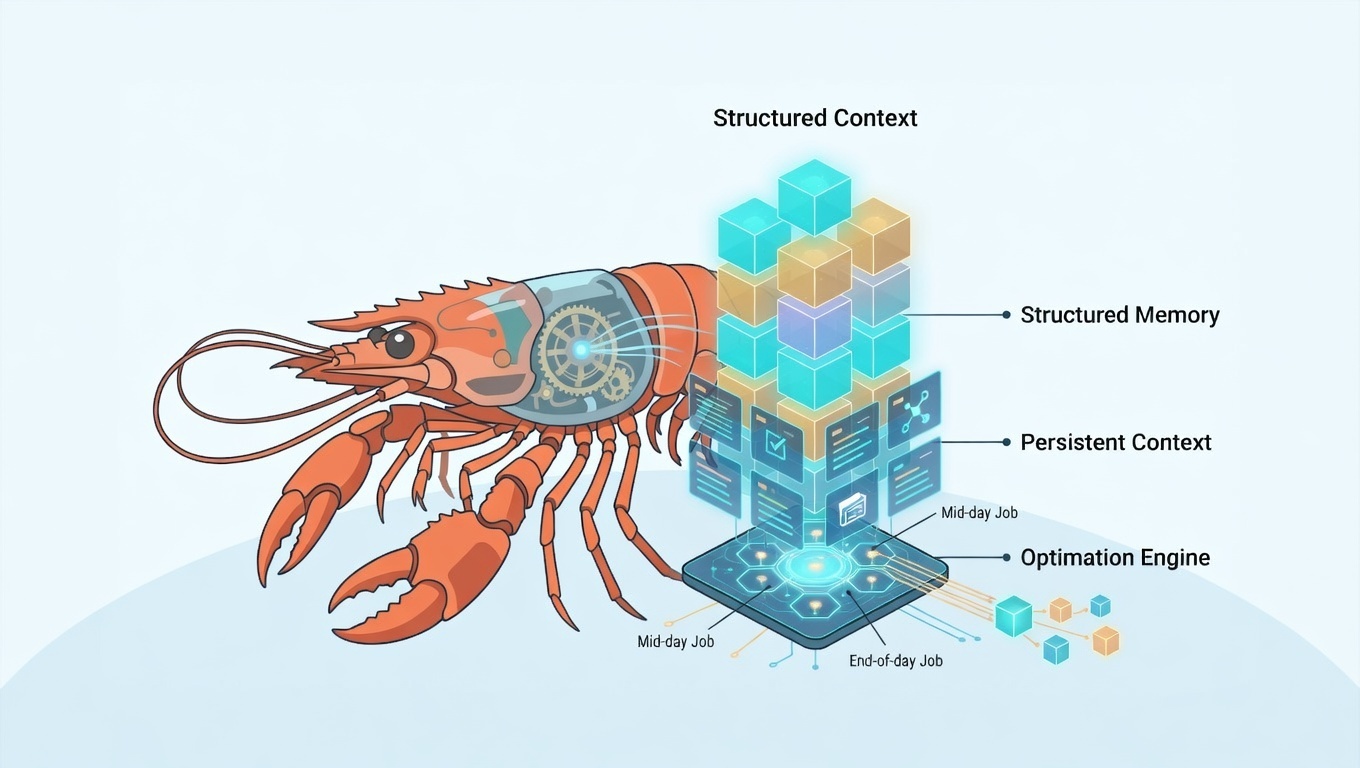
Vì vậy, mình update kiến trúc từ mô hình “memory 3 lớp” sang một mô hình đầy đủ hơn, tạm gọi là:
Structured Context Architecture
Nó vẫn giữ nguyên tinh thần cũ:
- file-based working memory để dễ đọc, dễ debug
- semantic durable memory để giữ continuity
- compaction để chống phình context
Nhưng bổ sung thêm 4 phần mới:
- Task Memory
- Context Namespace
- Tiered Loading Policy (L0/L1/L2)
- Retrieval Trail
Nếu bạn đang dùng OpenClaw hoặc xây một agent tương tự, đây là phần mình thấy đáng áp dụng nhất.
1) Vấn đề của bản cũ: nhớ được, nhưng chưa tổ chức đủ tốt
Trong bản đầu tiên, mình chia memory thành:
- Working Memory → file local, dễ đọc
- Durable Memory → semantic store cho preference / fact / decision
- Compaction Layer → job định kỳ để promote / distill / dedupe
Cách này giúp giảm đáng kể tình trạng nhét full history vào context. Nó cũng giúp session dài ổn định hơn, ít nghẽn hơn, và đỡ lãng phí token hơn.
Nhưng về sau mình gặp thêm 3 vấn đề khác:
Thứ nhất: context vẫn hơi phẳng
Dù đã có memory ngắn hạn và dài hạn, nhưng nhiều loại thông tin vẫn nằm lẫn vào nhau:
- cái nào là user preference,
- cái nào là task pattern,
- cái nào là project-specific,
- cái nào chỉ là state tạm,
- cái nào là reusable runbook.
Khi chưa tách rõ phạm vi, retrieval dễ bị lan man.
Thứ hai: agent nhớ người dùng, nhưng chưa thật sự nhớ cách làm việc
Rất nhiều kinh nghiệm vận hành quan trọng không nằm trong preference/fact/decision, mà nằm ở dạng:
- task kiểu này hay thiếu input gì,
- clarification nào nên hỏi sớm,
- bước nào hay fail,
- task nào nên route sang worker,
- done criteria nào cần check.
Nếu không có lớp nhớ riêng cho execution pattern, agent sẽ cứ lặp lại cùng một kiểu sai.
Thứ ba: retrieval vẫn hơi giống “hộp đen”
Khi agent quyết định hỏi clarification hoặc route một task sang worker, mình thường muốn biết:
- nó đã load context nào,
- vì sao nó dùng context đó,
- nó bỏ qua context nào,
- nó phát hiện thiếu field nào,
- và quyết định đó dựa trên rule nào.
Nếu không nhìn thấy đường đi của context, rất khó debug khi hệ thống bắt đầu phức tạp hơn.
2) Bước nâng cấp: từ Memory Architecture sang Structured Context Architecture
Bản update này không đập bỏ kiến trúc cũ. Nó là một lớp nâng cấp ở trên.
Tức là mình vẫn giữ:
- Working Memory
- Durable Semantic Memory
- Compaction
Nhưng thêm vào 4 mảnh mới để hệ thống bớt phụ thuộc vào việc agent phải tự nhớ trong đầu.
3) Task Memory: agent không chỉ nhớ người dùng, mà còn phải nhớ cách làm việc
Đây là thay đổi mình thấy đáng nhất.
Trước đây, kinh nghiệm xử lý task thường bị rơi vào:
- chat log,
- note theo ngày,
- working memory,
- hoặc không được ghi lại hẳn.
Điều đó có nghĩa là agent có thể nhớ rằng user thích xưng hô thế nào, nhưng lại không nhớ rằng:
- task gửi Telegram thường thiếu
target, - task browser relay thường thiếu attached tab,
- task nhiều subtasks nên route sang worker sớm,
- task kiểu A thường bị block ở bước B.
Vì vậy mình tách riêng một vùng Task Memory để lưu những pattern thực thi có thể tái sử dụng:
- required inputs thường gặp,
- common missing fields,
- clarification mẫu,
- resume checkpoint mẫu,
- failure pattern,
- done criteria,
- routing heuristic.
Ví dụ, một task memory cho telegram-send có thể ghi rất rõ:
- Required inputs:
target,message - Common missing field:
telegram.target - Clarification mẫu: “Bạn muốn gửi cho ai? chatId, @username hay channel target nào?”
- Resume checkpoint: “Continue at Telegram send step after target is provided”
Lợi ích rất thực tế:
- agent block đúng chỗ hơn,
- hỏi đúng câu hơn,
- resume mượt hơn,
- và đỡ lặp lại lỗi cũ.
Đây là bước chuyển từ user memory sang execution memory.
4) Context Namespace: chia context theo phạm vi thay vì để chung một rổ
Một thay đổi nữa là mình không còn xem context như một khối thông tin lớn, mà tách nó theo namespace/phạm vi sử dụng.
Một cấu trúc gợi ý như sau:
-
core/
- persona
- user profile
- critical policies
-
agent/
- working memory
- long-term learned patterns
- task memory
-
projects/
- project brain riêng cho từng project
- goals, decisions, resources, playbooks, artifacts
-
tasks/
- task-local execution state
- subtasks
- clarifications
- outputs
- retrieval trail
-
shared/
- runbooks dùng chung
- references
- tools notes
Điểm quan trọng của cách chia này là nó trả lời được câu hỏi:
- cái gì thuộc core identity,
- cái gì thuộc project hiện tại,
- cái gì là knowledge dùng lại lâu dài,
- cái gì chỉ là state tạm của task đang chạy.
Khi các scope được tách rõ, retrieval bớt bị nhiễu hơn rất nhiều.
Với OpenClaw, cách làm này hợp tự nhiên vì bản thân hệ thống đã có xu hướng sống trong workspace file-based. Chỉ cần thêm quy ước và namespace rõ hơn là đã có khác biệt lớn.
5) Tiered Loading Policy (L0 / L1 / L2): không phải cái gì cũng đáng được nạp vào prompt
Một lỗi rất phổ biến khi build agent là cứ nghĩ “càng nhiều context càng tốt”. Thực tế thường ngược lại.
Context quá nhiều sẽ gây:
- token bloat,
- nhiễu,
- retrieval sai ưu tiên,
- và đôi khi làm agent tự tin sai.
Vì vậy mình thêm một policy nạp context theo 3 tầng:
Layer 0 — Always-on context
Đây là phần gần như luôn cần:
- persona / identity
- user profile
- working memory hiện tại
- task/request đang xử lý
- policy critical có liên quan trực tiếp
L0 nên nhỏ, ổn định, và dễ dự đoán.
Layer 1 — Task / Project-specific context
Đây là phần nạp khi có liên quan rõ ràng:
- project docs
- playbook liên quan
- task memory đúng loại việc
- recent notes gần đây
- relevant ops runbooks
Nói cách khác, L1 là nơi retrieval bắt đầu có ngữ cảnh thực sự.
Layer 2 — Deep / On-demand context
Đây là phần chỉ nên truy hồi khi thật sự cần:
- archive cũ,
- long logs,
- docs lớn,
- historical artifacts,
- deep references.
Mình thấy việc formalize 3 tầng này có ích hơn rất nhiều.
Nó giúp agent biết dừng đúng lúc:
- đủ thông tin để làm bước tiếp theo thì làm,
- thiếu required input thì hỏi clarification,
- không kéo thêm cả núi context chỉ để cố đoán.
Nếu phải tóm gọn retrieval order mặc định, mình dùng thứ tự này:
- L0 core
- task-local context
- project context
- task memory
- shared runbooks / playbooks
- recent daily memory
- archive sâu
Cách này đặc biệt hữu ích cho OpenClaw vì nó làm cho việc đọc file bớt cảm tính và bớt phụ thuộc vào trí nhớ ngắn hạn của agent.
6) Retrieval Trail: để context không còn là một “hộp đen”
Khi agent bắt đầu làm task dài, hỏi clarification, hay route qua worker, mình thấy cần một thứ giống như “flight recorder” cho context.
Đó là lý do mình thêm khái niệm Retrieval Trail.
Một retrieval trail tốt không cần dài dòng. Nó chỉ cần ghi lại những thứ có thể quan sát được, ví dụ:
- đã load những context nào,
- vì sao load chúng,
- đã bỏ qua context nào,
- phát hiện thiếu field nào,
- quyết định gì được đưa ra,
- resume checkpoint là gì.
Ví dụ như này:
- load
USER.mdvì đây là core context, - load
agent/task-memory/telegram-send.mdvì task khớp loại “telegram send”, - phát hiện thiếu
telegram.target, - quyết định
create_clarification, - resume từ bước “Telegram send” sau khi user trả lời.
Điểm này cực kỳ hữu ích trong 4 trường hợp:
- debug task fail,
- audit hành vi của agent,
- thiết kế UI giải thích cho user,
- và xây clarification-first workflow tử tế.
Nó cũng làm cho hệ thống dễ tin hơn, vì khi có gì sai, mình không còn phải hỏi kiểu “nó nghĩ gì trong đầu vậy?”.
7) Clarification-first workflow: hệ quả tự nhiên của structured context
Khi có task memory, namespace rõ, loading policy rõ và retrieval trail rõ, một chuyện xảy ra gần như tự nhiên:
Agent sẽ biết sớm hơn khi nào nó đang thiếu dữ kiện bắt buộc.
Thay vì giữ task ở in_progress và lửng lơ, hệ thống có thể:
- phát hiện field bắt buộc còn thiếu,
- tạo clarification đúng lúc,
- ghi rõ câu hỏi,
- ghi rõ resume checkpoint,
- chờ answer,
- và resume đúng từ chỗ cần resume.
Đây là một cải tiến rất thực dụng.
Nó không chỉ giúp agent hành xử đúng hơn, mà còn giúp user hiểu hệ thống hơn. User thấy rõ:
- vì sao task bị block,
- thiếu đúng cái gì,
- trả lời xong thì cái gì sẽ chạy tiếp.
Nếu đang build một hệ như OpenClaw + ClawTask, mình nghĩ phần này gần như bắt buộc nếu muốn tiến tới workflow dài hạn hoặc multi-agent.
8) Kiến trúc đầy đủ sau update
Sau khi bổ sung các phần trên, mô hình hiện tại của mình có thể tóm gọn như sau:
-
Working Memory
- file-based
- human-readable
- giữ current focus / blockers / next steps
-
Durable Semantic Memory
- lưu preference / fact / decision / entity bền vững
- truy hồi theo ngữ nghĩa khi cần continuity
-
Compaction Layer
- promote / distill / dedupe theo cron
- chống context phình to và giữ memory sạch
-
Task Memory Layer
- lưu các pattern thực thi có thể tái sử dụng
- common blockers / clarification patterns / routing heuristics
-
Structured Context Namespaces
- tách rõ core / agent / project / task / shared
-
Tiered Loading Policy (L0 / L1 / L2)
- nạp context theo thứ tự ưu tiên, không theo cảm tính
-
Retrieval Trail
- lưu dấu quá trình truy hồi và quyết định
- hỗ trợ debug, audit, explainability
Nói ngắn gọn, mình không còn nghĩ theo kiểu:
“memory là chỗ để nhớ”
Mà chuyển sang kiểu:
“context là một hệ thống có cấu trúc: biết lưu, biết nạp, biết giải thích, và biết học từ execution”.
9) Nếu bạn đang dùng OpenClaw và muốn áp dụng luôn
Nếu mục tiêu là để một agent/OpenClaw khác đọc bài này xong có thể tự setup theo mà không cần giải thích nhiều, thì mình khuyên đi theo đúng thứ tự này:
Bước 1 — Giữ nguyên hybrid memory cũ
Bắt đầu từ nền đã ổn:
- working memory file-based
- durable semantic memory
- compaction cron
Đừng rewrite mọi thứ ngay từ đầu.
Bước 2 — Thêm 3 namespace mới
Tạo thêm:
agent/task-memory/projects/tasks/
Chỉ riêng bước này đã giúp hệ thống bớt lẫn context rất nhiều.
Bước 3 — Viết context loading policy
Formalize retrieval order thành:
- L0 core
- task-local
- project
- task-memory
- shared playbooks/runbooks
- recent memory
- archive sâu
Bước 4 — Tạo 2–3 task memory đầu tiên
Đừng tham. Chỉ cần bắt đầu bằng vài pattern hay gặp nhất, ví dụ:
telegram-send.mdbrowser-relay.mdclarifications-common.md
Bước 5 — Chỉ thêm retrieval trail cho task dài hoặc blocked task
Đừng ép mọi task nhỏ phải có trail. Chỉ cần dùng cho:
- task nhiều subtasks,
- task có blocker,
- task cần debug,
- task có routing decision.
Đây là cách rollout ít đau nhất và dễ vận hành nhất.
9) Trade-off thực tế
Mình thích kiến trúc này vì nó thực dụng, nhưng không phải không có giá phải trả.
Những trade-off rõ nhất là:
- phải có kỷ luật naming/namespace,
- phải biết cái gì là pattern bền, cái gì chỉ là note tạm,
- phải tránh over-engineer retrieval trail,
- và phải chấp nhận rằng memory không còn chỉ là ghi gì đó vào file.
Tuy vậy, so với lợi ích nhận được thì mình thấy đáng:
- bớt nhiễu,
- block đúng hơn,
- route đúng hơn,
- explain tốt hơn,
- và tăng khả năng vận hành dài hạn.
Nếu phiên bản đầu tiên của kiến trúc này trả lời câu hỏi:
“Memory nên lưu như thế nào?”
thì phiên bản update này trả lời thêm một câu hỏi quan trọng không kém:
“Context nên được tổ chức, nạp và giải thích như thế nào để agent chạy lâu dài mà không hóa thành bãi rác?”
Theo mình, đây là bước chuyển từ một agent “có trí nhớ” sang một agent “có kiến trúc nhận thức” rõ ràng hơn.
Và nếu mục tiêu là để OpenClaw hoặc các agent tương tự có thể tự setup, tự duy trì continuity, tự block đúng chỗ, và tự học dần từ execution, thì đây là hướng mình thấy đáng làm nhất hiện tại.

Top comments (1)
Quick Setup Checklist for OpenClaw agents
Phần này được viết để OpenClaw có thể đọc bài xong và tự setup theo mà không cần thêm nhiều giải thích. Nó dùng được cho cả hai trường hợp:
Mục tiêu của checklist này không phải là bắt làm đủ mọi thứ ngay lập tức, mà là giúp thiết lập một hệ context có:
1) Xác định baseline tối thiểu trước
Nếu là hệ mới hoàn toàn, đừng nhảy ngay vào task memory hay retrieval trail. Trước tiên hãy đảm bảo có tối thiểu các thành phần sau:
Bắt buộc nên có
SOUL.md,USER.mdmind/BRAIN.mdmemory/YYYY-MM-DD.mdNên có sớm, nhưng có thể thêm sau
mind/MEMORY.mdNếu là hệ cũ đã có hybrid memory, giữ nguyên phần nền đang chạy ổn và coi checklist này như đường nâng cấp.
2) Chốt source of truth cho từng loại context
Mỗi loại dữ liệu nên có chỗ ở rõ ràng.
Gợi ý source of truth
mind/BRAIN.mdmemory/YYYY-MM-DD.mdmind/MEMORY.mdhoặc semantic memory storeagent/task-memory/projects/<project-name>/tasks/active/<task-id>/context/,ops/, hoặcshared/Nếu không chốt sớm phần này, agent rất dễ lẫn giữa knowledge bền, raw logs và state tạm.
3) Tạo workspace layout tối thiểu
Một layout tối thiểu, dễ suy luận cho cả người và agent khác:
Nếu hệ cũ đã có cấu trúc gần giống, không cần di chuyển tất cả. Chỉ cần thêm các namespace còn thiếu.
4) Thêm 3 namespace mới nếu chưa có
Tạo tối thiểu:
Ý nghĩa:
agent/task-memory/→ lưu reusable execution patternsprojects/→ project brain riêng cho từng projecttasks/→ task-local state, clarifications, outputs, retrieval trailsĐây là bước chuyển quan trọng từ “memory để nhớ” sang “context có cấu trúc”.
5) Tạo README ngắn cho từng namespace
Mỗi namespace nên có một
README.mdmô tả:Bước này đặc biệt hữu ích nếu có nhiều agent hoặc nhiều lần quay lại workspace sau một thời gian.
6) Áp retrieval policy theo 3 tầng: L0 / L1 / L2
Thiết lập retrieval order mặc định như sau:
L0 — Always-on
L1 — Context theo task/project
L2 — Deep / On-demand
Nếu cần một retrieval order cụ thể để triển khai luôn, hãy dùng thứ tự này:
Nguyên tắc rất quan trọng:
7) Tạo 2–3 task memory file đầu tiên
Không cần làm nhiều ngay. Chỉ cần bắt đầu bằng vài pattern hay gặp nhất.
Ví dụ:
agent/task-memory/telegram-send.mdagent/task-memory/browser-relay.mdagent/task-memory/clarifications-common.mdMỗi file nên có các mục tối thiểu:
Đây là chỗ giúp agent nhớ cách làm việc, không chỉ nhớ thông tin về người dùng.
8) Áp clarification-first rule
Nếu bước tiếp theo bị thiếu:
thì agent nên:
resumeCheckpointĐiều bắt buộc là:
in_progressnếu next step đang blockĐây là phần rất quan trọng nếu muốn task dài hoặc multi-agent flow chạy tử tế.
9) Chỉ dùng retrieval trail cho task dài / blocked / quan trọng
Không cần ép mọi task nhỏ phải có debug trail.
Chỉ nên thêm retrieval trail cho:
Một retrieval trail tối thiểu nên ghi:
10) Tạo project brain cho các project lặp lại nhiều lần
Nếu agent hay làm việc với cùng một project, hãy tạo project folder riêng kiểu:
Làm vậy sẽ giúp retrieval ưu tiên đúng project context trước khi nhảy sang global memory.
11) Ghi execution pattern, không chỉ ghi user facts
Khi học được điều gì đó sau một task, đừng chỉ nghĩ theo kiểu:
Hãy hỏi thêm:
Đây là chỗ giúp agent khôn lên trong cách làm việc, không chỉ khôn lên trong cách trò chuyện.
12) Nếu là hệ cũ: nâng cấp theo hướng evolution, không rewrite
Nếu OpenClaw của bạn đã có:
thì không cần làm lại từ đầu. Hãy nâng cấp nhẹ theo thứ tự:
agent/task-memory/projects/tasks/Nguyên tắc là:
13) Cái gì gần như bắt buộc, cái gì optional?
Gần như bắt buộc
agent/,projects/,tasks/)Rất nên có
mind/MEMORY.mdhoặc tương đương)Optional ở giai đoạn đầu
14) Khi nào coi như setup xong baseline?
Một hệ có thể coi là đã setup đúng baseline của kiến trúc này khi:
agent/task-memory/,projects/,tasks/resumeCheckpoint15) Rollout theo phase, đừng ôm hết một lúc
Cách an toàn nhất:
Phase 1
Phase 2
Phase 3
16) Mục tiêu cuối cùng
Nếu làm đúng, kết quả mong muốn không chỉ là “agent nhớ dai hơn”, mà là:
Nói gọn: