Hello anh em,
Bài này mình chia sẻ kiến trúc memory hiện tại mình đang dùng với OpenClaw sau vài vòng thử nghiệm. Mục tiêu là tăng độ nhớ đúng ngữ cảnh nhưng vẫn giữ context gọn và vận hành ổn định.
Tóm tắt nhanh cho anh nắm được
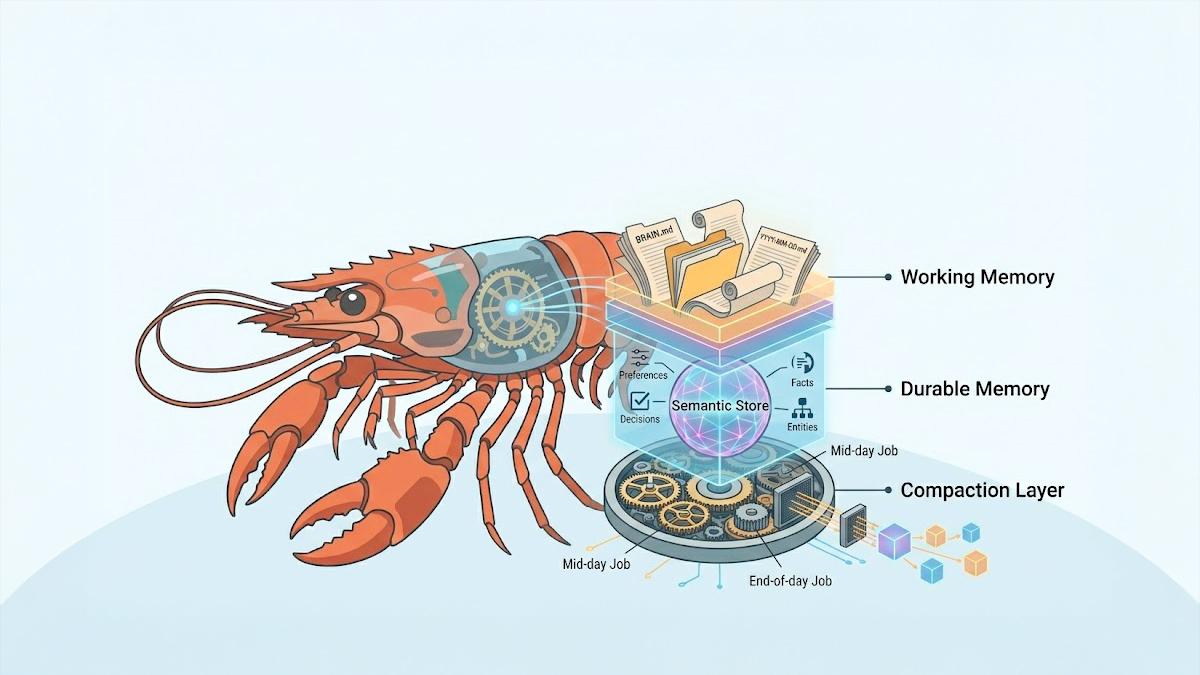
Mình không dùng kiểu "nhét full history vào context". Thay vào đó, mình sử dụng Hybrid Memory 3 lớp:
-
Working Memory (File-based):
-
mind/BRAIN.md: Trạng thái công việc hiện tại. -
memory/YYYY-MM-DD.md: Nhật ký công việc theo ngày.
-
-
Durable Memory (Semantic Store):
- Sử dụng Memory plugin (hiện tại là
memory-lancedb) để lưu các dữ liệu bền vững: preference, decision, fact, entity.
- Sử dụng Memory plugin (hiện tại là
-
Compaction Layer (Cron):
- Job giữa ngày: Lọc nhẹ và thúc đẩy (promote) các memory quan trọng.
- Job cuối ngày: Tổng hợp sâu, xóa trùng lặp (dedupe) và chắt lọc (distill).
Kết quả: Context sạch hơn, ít "quên vặt", và tiết kiệm token đáng kể khi chạy lâu dài.
Vì sao mình chuyển sang kiến trúc này?
Vấn đề mình gặp trước đây:
- Session dài: Model bắt đầu bị nhiễu thông tin.
- Trôi thông tin: Những quyết định cũ bị chìm nghỉm giữa chat log.
- Chi phí & Hiệu suất: Càng nhét nhiều context càng đắt và chậm, trong khi độ chính xác chưa chắc tăng.
Vì vậy, mình tách memory thành các lớp ngắn hạn/dài hạn kết hợp với Compaction định kỳ để duy trì chất lượng.
Chi tiết từng lớp
1. Working Memory (Ngắn hạn, dễ đọc)
Sử dụng file Markdown để giữ trạng thái "đang làm gì":
- Task hiện tại.
- Các rào cản (Blockers).
- Các việc cần theo dõi (Follow-up).
Ưu điểm: Người dùng có thể đọc (human-readable), debug cực dễ và không phụ thuộc vào Database ngay từ đầu.
Nhược điểm: Nếu không có compaction, file sẽ phình to và gây rối.
2. Durable Memory (Dài hạn, Semantic)
Lưu trữ những gì thực sự đáng nhớ:
- Thói quen và sở thích người dùng (User preference).
- Các quyết định kỹ thuật hoặc vận hành.
- Các sự thật (Facts) có tính lặp lại trong workflow.
Ưu điểm: Truy xuất (recall) theo ngữ nghĩa tốt hơn việc tìm kiếm văn bản thông thường. Giữ được tính liên tục (continuity) qua nhiều session.
Nhược điểm: Cần quản trị tốt (governance), nếu không sẽ trở thành "bãi rác vector".
3. Compaction (Trái tim của hệ thống)
Mình chạy 2 job định kỳ:
- Midday pass: Lọc nhanh các mục quan trọng.
- Nightly pass: Tổng hợp sâu, xóa trùng lặp và chuyển đổi thành memory bền vững.
Policy đang áp dụng (Rất quan trọng)
Write Policy (Cái gì được nhớ)
| Nên nhớ | Không nên nhớ |
|---|---|
| Preference ổn định | Tán gẫu (Chit-chat) |
| Quyết định & Lý do (Rationale) | Fact công khai dễ tìm lại |
| Milestone / Blocker / Next step | Nội dung nhạy cảm không cần thiết |
Retrieval Policy (Khi nào truy xuất)
- Nên: Khi câu hỏi liên quan đến lịch sử, quyết định hoặc sở thích; các task nhiều bước cần tính liên tục.
- Không nên: Khi câu hỏi mang tính chất chung chung, không liên quan ngữ cảnh cá nhân. Tránh lỗi "search first" cho mọi câu hỏi.
Injection Policy
- Chỉ inject từ 3–8 memory snippets hàng đầu.
- Ưu tiên theo thứ tự: Relevance > Importance > Recency.
- Luôn giữ giới hạn token (budget) cho khối memory.
Đánh giá thực tế
Ưu điểm
- Giảm tình trạng nghẽn context (context bloat) rõ rệt.
- Tăng độ ổn định cho các task dài hoặc đa bước.
- Dễ vận hành và audit/debug vì vẫn có file local để kiểm tra.
Nhược điểm / Trade-off
- Thêm các thành phần chuyển động (cron, policy, cleanup).
- Cần kỷ luật trong việc ghi nhớ để tránh nhiễu.
- Tốn thời gian tinh chỉnh ngưỡng (threshold) và top-k retrieval.
Lộ trình triển khai khuyến nghị
Để tránh việc quá sa đà vào kỹ thuật (over-engineer), bạn nên:
- Bắt đầu với File-based memory và thiết lập policy rõ ràng.
- Kích hoạt Semantic memory store (LanceDB hoặc pgvector).
- Thêm Compaction cron.
- Sau 1 tuần mới tiến hành benchmark và tinh chỉnh (tune).

Top comments (0)